Guidelines:
Universal Data Access (UDA) Design
This material is provided courtesy of Applied Information
Sciences, Inc.

Topics
References 
http://www.microsoft.com/data
http://msdn.microsoft.com/library/psdk/dasdk/choo0wvn.htm
Summary
Microsoft®Universal Data Access® (UDA) technology provides
standardized access to a variety of relational and non-relational information
sources. The programming interfaces defined by UDA are tool and language
independent and support the ability to integrate data from diverse data sources.
The primary deployment artifact for UDA technologies is Microsoft Data Access
Components® (MDAC). MDAC can be deployed in a variety of architectures,
including desktop applications, two-tier client/server applications and
distributed, n-layer/n-tier applications. MDAC includes the following data
access Application Programming Interfaces (APIs):
These guidelines will first describe the characteristics and
features of each of the data access APIs and then describe optimization
techniques for each. Next, scenarios will be described to demonstrate when and
where each of the UDA technologies should be applied. Finally, a discussion on
how UDA technologies fit into the application design process is presented.
Each of the UDA technologies exposes a different API and a
different set of features, for different types of environments and applications.
Each of the UDA technologies can be used in conjunction with the others in a
layered approach. This means that the API selection can be based upon the
features of the API and not on whether or not an OLE DB provider or ODBC driver
has been written for a particular data source. The figure below depicts the
relationships between the different UDA technologies.
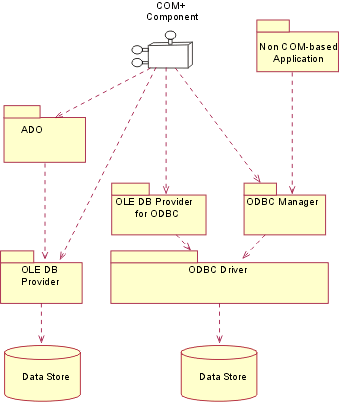
UDA Technologies
As shown in the figure, OLE DB providers and ODBC drivers are
the UDA components that directly access data sources. The ODBC Manager, which is
an MDAC component, exposes the ODBC API to ODBC clients. To make ODBC data
sources available to OLE DB consumers, Microsoft provides another MDAC component
called the OLE DB provider for ODBC. This component converts to and from the OLE
DB API to the ODBC API and plays the role of an ODBC manager to an ODBC driver.
At the highest level is ADO. ADO does not directly access any data sources, but
instead uses OLE DB providers to access data. The following sections describe
the characteristics and features of ODBC, OLE DB and ADO.
ODBC is a widely supported application programming interface
(API) for data access. It is based on the Call-Level Interface (CLI)
specifications from X/Open and ISO/IEC for database APIs and uses Structured
Query Language (SQL) as its primary database access language. ODBC includes the
following features and characteristics:
-
C Language API based
-
Large number of drivers available for a wide variety of data
sources
-
Well suited for accessing data from relational data
sources
-
Supports both SQL and procedure-based data access
techniques
-
Support on non-Windows platforms
OLE DB is a Component Object Model (COM)-based data access API
that was developed after ODBC. OLE DB was designed to not only provide access to
relational data, but also to non-relational data in an efficient manner. Because
of its COM-based interface, the API has easily been evolved and enhanced to add
new features such as Online Analytical Processing (OLAP) and data mining
support. OLE DB includes the following features and characteristics:
ADO is a high level interface exposing OLE DB provider data to
OLE automation clients. It was designed to simplify earlier data access APIs
such as Data Access Objects (DAO) and Remote Data Objects (RDO) by flattening
their hierarchical programming models. It also supports advanced features such
as disconnected record sets and is accessible to all automation-compliant
languages such as VBScript, Jscript and Visual Basic. ADO includes the following
features and characteristics:
The following sections describe optimization techniques that can
be applied to all of the UDA-based technologies.
Typically, one of the most expensive resources in gaining access
to the information contained in a data source is the connection to the data
source itself. This is particularly true when the consumer of the data is
located on a different machine than the data source itself. When designing
applications, the number of connections to a data source should be kept to a
minimum and the duration that the connection to the data source is kept open
should also be minimized. This can be achieved by using the following guidelines
when building data access applications:
-
Perform as much work as possible before the connection is
opened
-
Minimize the amount of work that is performed while the
connection is open
-
Whenever possible, reuse connections
This approach, when used in conjunction with the following
guidelines on connection and session pooling, maximize connection usage.
The ODBC manager and the OLE DB service components provide
connection and session pooling respectively. Connection/session pooling is a
management service that pools open connections/sessions to data sources. When an
application requests a new connection to a data source, the connection/session
manager examines the list of currently connected, but unallocated connections.
The security and other properties of the connection are respected. Pooled
connections are reused only if all requested properties match what has been
requested.
Pooling is intended to improve the performance of connecting and
disconnecting in large n-tier applications by keeping a pool of live connections
open on the middle tier for a short period of time and then reusing them for new
connection requests. This allows middle-tier applications that rely on quick,
individual database actions to share connections rather than having to create
and release connections for each action. Note that the techniques described in
the previous Connection Usage section maximize the effectiveness of connection
and session pooling.
Efficient record set management defines how the cursor or record
set of data that results from a query is created and managed. Two considerations
should be taken into account when creating record sets:
-
Use client-side cursors to maximize performance. There are
only a few scenarios, such as when you are retrieving a very large data set,
in which it makes sense to use server-side cursors; otherwise, client-side
cursors make the most efficient use of network bandwidth and machine
resources. Additionally, when using ADO, as the access API, whenever the
record set is being used in a read-only scenario, or the record set needs to
be used for a long period, the record set should be disconnected from the
connection. Then the connection can be closed, which returns it to the
connection pool for reuse by other threads of the application.
-
Another record set management consideration to make is the
type of cursor that is opened. The most efficient type of cursor that can be
opened is a forward-only, read-only cursor. If it is necessary to update
data, it is typically most efficient to retrieve data using a forward-only,
read-only cursor and to then create an SQL statement to perform the
necessary updates. Only use other type of cursors, such as dynamic, keyset
or static, when absolutely necessary.
All of the UDA-based APIs support some form of asynchronous
execution. The typical scenario is to initiate a data access request using an
asynchronous API call and to check back for a completion station at a later
time. In a well-designed, multi-threaded application, the thread of execution
that initiates the data access request can perform some meaningful work while
it, or another thread, polls for the request result.
Regardless of the data source being accessed, if stored
procedures are available, they should typically be used instead of standard SQL
statements. In most databases, when stored procedures are created, they go
through the parsing and normalization steps that occur at runtime against
standard SQL statements. Another advantage of stored procedures is that client
requests will use less network bandwidth than equivalent SQL statements sent to
the server because they are inherently less verbose.
Stored procedures can provide even greater performance gains
when they efficiently leverage database-processing power. This typically
involves minimizing the amount of data that is returned to the UDA client by
performing appropriate levels of processing in the stored procedure.
Balancing the amount of work that is performed within the stored procedure,
against the amount of work that is performed in a UDA client needs to be done on
a case-by-case basis to achieve maximum performance.
Several other optimization techniques should be taken into
consideration when designing UDA-based applications.
-
When an application is using ADO or OLE DB as its UDA API,
use native OLE DB providers (instead of the OLE DB provider for ODBC in
conjunction with an ODBC driver). Native OLE DB providers will typically be
faster and have a smaller memory and disk footprint than the OLE DB provider
for ODBC used in conjunction with an ODBC provider.
-
When using Visual Basic with ADO, declare all variables
(including objects) and strongly type them. This will cause Visual Basic to
not create variables as variants. Variants are inefficient.
-
Minimize the amount of data queried for by formatting the
data access request to minimize the number of columns in the result set. For
example, instead of using the SQL command SELECT * FROM, select only
the columns that are required by the query.
Each of the UDA technologies, ODBC, OLE DB and ADO provide
features that make them well suited for certain architectures. The following
sections describe when and where to use each of the technologies.
Two tier applications combine the presentation, business logic
and data layers of an application on a single machine, while the data services
portion of the application resides on another machine. The data layer of the
application directly accesses the data source using one of the UDA technologies.
Legacy, non-COM applications should utilize ODBC as the data access API because
this is the simplest and most efficient method available to them. Also,
applications that may be ported to non-Windows platforms should utilize ODBC
because ODBC is supported on numerous non-Windows platforms. Applications
written in C++ can use either OLE DB or ADO. If a very low level of control over
the data access portion of the application is required, then OLE DB is
preferable. If the presentation or business logic layers of the application are
written in a language that does not support the COM-interface exposed by OLE DB,
then ADO should be used to simplify the transfer of data to the higher layers.
Finally, applications written in languages that do not support COM
interface-based programming should utilize ADO to access data.
N-Tier, thick Web client applications are typified by their use
of HTML/Dynamic HTML (DHTML)/eXtensible Markup Language (XML), client-side
scripting, ActiveX controls and other browser-specific features. Internet and
Intranet sites that can control or dictate the type of browser that will be used
to access their content, will construct presentation tiers using this client
type. This style of application can take advantage of ADOs Remote Data
Service (RDS). RDS provides a mechanism for ActiveX-enabled browsers such as
Microsoft Internet Explorer® to directly access OLE DB accessible data sources
across the Internet and through firewalls. RDS can also be used to instantiate
COM-based business objects and transfer data to and from those COM business
objects using ADO recordsets. RDS supports client-side caching of result sets
and provides automatic binding with data-aware ActiveX controls and DHTML
elements. RDS, scripting and DHTML can be used to minimize the number of
round-trips to the Web server for validation, data retrieval and data updates.
It should be noted that much of this type of functionality is also available in
the XML Document Object Model (XMLDOM) that is part of Microsoft Internet
Explorer versions 5.0 and higher. However, this technology is not addressed in
these guidelines because it is not part of the current UDA framework.
The backend tiers of an n-tier, thick Web client application can
be built using any of the UDA technologies. However, when ADO and RDS are being
used to transfer disconnected recordsets to the thick Web client application,
the best API to use on the backend is ADO. Although ADO recordsets can be
manually constructed from ODBC or OLE DB data sources, it is simpler and more
efficient, to use ADO to perform the recordset creation step.
The other types of n-tier applications such as rich native
client and thin Web client applications have common design characteristics. Both
types of applications can use any of the UDA APIs. ODBC would only be used in
cases where existing ODBC drivers could not be used with the OLE DB provider for
ODBC. Refer to the appropriate Microsoft documentation for limitations of the
ODBC provider for ODBC. The choice of OLE DB vs. ADO is based upon the same
criteria as was defined for other architectural models.
Applications written in C++ can use either OLE DB or ADO. If a
very low level of control over the data access portion of the application is
required, then OLE DB is preferable. If the presentation or business logic
layers of the application are written in a language that does not support
COM-interface programming, then ADO should be used to simplify the transfer of
data to the higher layers. Applications written in languages such as Visual
Basic, VBScript and JavaScript, that do not support the COM interfaces exposed
by OLE DB, should utilize ADO to access data.
In the standard three-layer logical architecture model for
Windows DNA-based applications, UDA technologies can be used in the design of
data access components in the business logic or data layers. Alternatively, in
n-layer logical architecture models, the data access components that utilize the
APIs provided by the UDA technologies are often grouped into a separate data
access layer that is between the business logic and data layers. See the Guidelines:
Windows DNA Sample Architecture Patterns and Implementation Mechanisms for
more information on logical architecture models.
In the Analysis and
Design discipline, during the Workflow
Detail: Analyze Behavior, the designer defines Unified Modeling Language
(UML) interaction diagrams for modeling the dynamic behavior of the objects that
participate in a use case. The designer should consider using the «entity»
analysis class stereotype for modeling the objects and classes that will be
implemented in the data access components. The «entity»
analysis class is used to model classes that have responsibilities for storing
and managing information in the system. Refer to Guidelines:
Analysis Class for more information on the «entity»
analysis class stereotype.
For Windows DNA-based applications developed using Microsoft
Visual Basic®, the designer may alternately use a pre-defined Windows DNA
specific class stereotype in Rational Rose to model the data access classes.
This stereotype is the «ADO Class»
stereotype. When the designer creates a class in Rational Rose with the
stereotype «ADO Class», Rational
Rose automatically creates several commonly used properties and methods that
facilitate the use of ADO services. Refer to the Rational Rose help topic Rose
Visual Basic for more information on using Visual Basic specific stereotypes.
Copyright
© 1987 - 2001 Rational Software Corporation
|  Artifacts >
Artifacts >
 Analysis & Design Artifact Set >
Analysis & Design Artifact Set >
 Software Architecture Document >
Software Architecture Document >
 Guidelines >
Guidelines >